Bespoke software, and a really simple RSS aggregator
This week I built myself an RSS1 aggregator2. There are a couple of websites that are written by friends, or are of high enough quality that I want to read everything published on them, not just the things that are popular enough make their way to me via Hacker News or similar.
I had fun building it, and I think its design is interesting, so let's take a look at how it works. I'll also use it as an example to talk about the sort of bespoke software that I've really been enjoying writing recently.
How the RSS aggregator works
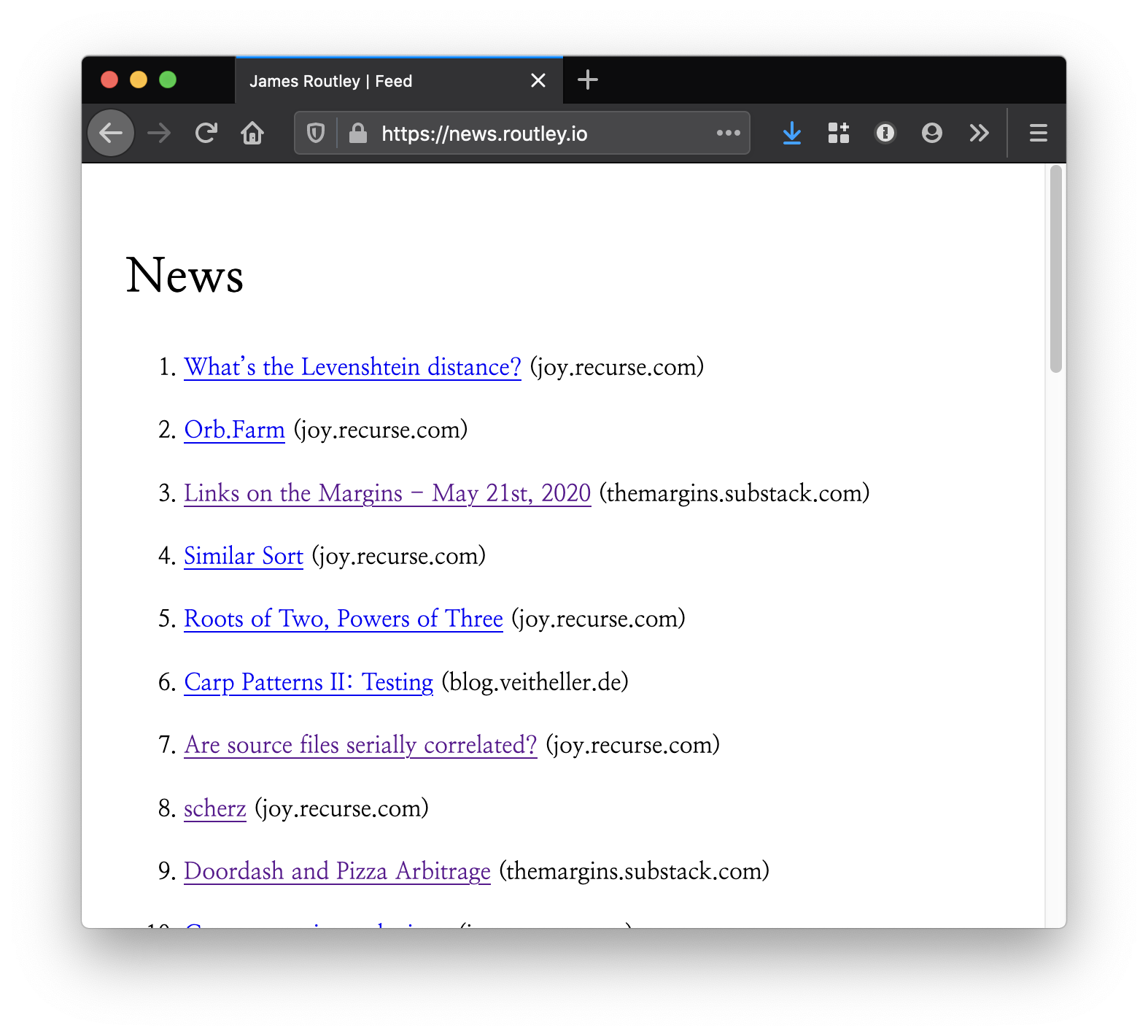
This is what it looks like. It's a webpage, hosted at news.routley.io, which contains links to the last 30 days worth of posts from each of the blogs I subscribe to.
The website and the code which generates it are stored in a single GitHub repo, and it works by gluing together a couple of GitHub features.
Generating the web page
I wrote a simple Go script, which stores a list of RSS feeds I subscribe to. When the script is run, it:
- Iterates over the feeds, fetches the list of posts from each one, and stores them in a big list of all posts
- Uses Go's HTML templating package to generate a self-contained HTML page containing the list of posts
- Saves this HTML page as a file in the repo, at
docs/index.html
Serving the webpage
Github Pages is enabled for the repo. It serves the contents of the docs
directory (which just contains the index.html file) on my custom domain
news.routley.io.
Updating the webpage
I created a GitHub Action which:
- Pulls the repo
- Runs the Go script to generate the website
- Commits any changes to
index.html, and pushes them back to the repo
This action is triggered by a cron, and runs every hour. When the updated
index.html is pushed to the repo, GitHub Pages automatically updates the
website.
Bespoke software
Historically, I would have built this as a CLI tool, so other people could use it to generate their own RSS aggregators. This adds a number of things I'd need to think about. For example I'd need to:
- Define a way to let people specify feeds to pull posts from. This would probably be a config file with a pre-defined syntax, which we'd need to read and parse.
- Let the user specify the name of the file to output HTML to in case they don't want to use GitHub Pages.
- Let users specify their own CSS, rather than hard coding it into the HTML template.
- Store the code which generates the RSS aggregator to be in a separate repo from the repo which stores and serves my RSS aggregator, so users can clone or fork it without getting things specific to my aggregator.
- Update the script to read multiple feeds concurrently, so it remains fast for users who subscribe to large numbers of feeds.
None of these are particularly difficult to add, but each adds to the total complexity of the project. In my day job as a software engineer, I write a lot of code which is 'used' by other people - sometimes directly, but also indirectly when they read it, make changes to it and keep it running in production. Writing code that other people use requires extra work. Sometimes it's nice to step back from it and write code that's just for yourself.
(By the way - if enjoyed this post and would like to follow me, I've also got an RSS feed)
-
RSS stands for 'Really Simple Syndication'. It's a protocol that lets websites list their content in a machine-readable format. Applications can read RSS feeds to pull content from multiple websites into one place. ↩︎
-
I call it an 'RSS aggregator' rather than the more common 'RSS reader' because mine doesn't let you read any of the content directly - it just links out to the source webpages. ↩︎